
PR
あなたのAIは「見た目」ではなく「データ」を読んでいる

ChatGPTに資料を読ませたり、ClaudeにWebページを解析させたりする機会が増えている。AIアシスタントは非常に賢く見えるが、実は根本的な「弱点」を抱えている。
それは、AIは「人間の目に映る文字」ではなく「HTMLやテキストデータの中身」しか読んでいないという事実だ。
この一文を読んで「それの何が問題なの?」と思った人こそ、今回の記事を最後まで読んでほしい。2025年末にセキュリティ企業・LayerX Securityが公表した「Poisoned Typeface(毒された書体)」攻撃は、まさにこの盲点を突いた、驚くほどシンプルかつ強力な手法だ。
人間とAIの”見え方”はそもそも違う
まず基本的なことを押さえておこう。私たちがWebブラウザでページを開くとき、画面上に表示される文字はフォント(書体)によって描画されている。
たとえば「A」という文字が表示されるとき、裏側では「コード`0x41`が来たら『A』の形を描画する」というルールが働いている。このルールのことをグリフマッピングと呼ぶ。
人間はブラウザが描画した「見た目の文字」を読む。一方、AIアシスタントがページを解析するときは、ブラウザが描画する前の生のHTMLコード(テキストデータ)を読む。
この「見た目」と「データ」の乖離こそが、今回の攻撃の出発点になっている。
フォントを使って「表示」と「実体」を別々にできる
Webページで使うフォントは、CSSと専用のフォントファイルを用意するだけで自由にカスタマイズできる。
通常はデザイン目的で使われるこの仕組みを悪用すると、グリフマッピングを意図的に入れ替えたカスタムフォントを作ることができる。
つまり、「このコードが来たら本来と違う文字の形を描画する」というルールを自分で書けてしまうのだ。JavaScriptは一切不要。CSSとフォントファイルだけで完結する。
ここまで読んだだけでは「それで何ができるの?」と感じるかもしれない。次のセクションで、実際の攻撃の仕組みを具体的に説明しよう。
Poisoned Typeface(毒された書体)攻撃とは何か

LayerX Securityが2026年3月に公開したレポートで明らかになったこの攻撃手法は、「人間が見る文字」と「AIが読む文字」を意図的に乖離させることで、AIの安全チェックをすり抜けることを目的としている。
名前の通り、フォント(書体)そのものを「毒する」攻撃だ。
フォントの「文字の割り当て」を入れ替えるだけでAIが騙される
具体的な仕組みをできるだけわかりやすく説明しよう。
攻撃者がカスタムフォントを使ったWebページを用意するとする。そのHTMLファイルの中には、データとして「rm -rf /」という文字列が書かれている。これはLinuxサーバーのファイルをすべて削除してしまう、非常に危険なコマンドだ。
しかし、カスタムフォントの定義では次のように設定されている:
「r」のコードには「お」の形を、「m」のコードには「す」の形を、スペースには「す」の形を……といった具合にグリフを入れ替える。
その結果、ブラウザ上では「おすすめのレシピはこちら」のような無害な文章として表示される。
この状態でユーザーがAIに「このページの内容を要約して」「このコマンドを実行しても安全?」と尋ねると、AIは画面に表示されている「おすすめのレシピ」ではなく、HTMLデータの中にある「rm -rf /」という生のテキストを読む。
フォントの描画ルールを知らないAIは、表示と実体の乖離に気づけない。人間には無害に見えるページが、AIには危険なコマンドとして届く。これがPoisoned Typefaceの核心だ。
逆パターンも同様に機能する。悪意ある命令をHTMLデータに書いておきながら、フォントで「無害な文章」として人間の目に映るよう偽装することも可能だ。
実際にこんな悪用ができてしまう
この攻撃が現実の脅威として深刻な理由は、悪用のバリエーションが広いからだ。
・プロンプトインジェクション:AIに特定の操作をさせる隠し命令を、ページ内に人間に気づかれないよう埋め込む
・安全チェックのすり抜け:AIによるコンテンツ審査ツールに、危険なテキストを「無害」と誤判定させる
・フィッシング支援:人間が読むと正常に見えるページに、AI経由での操作命令を仕込む
特に怖いのは、JavaScriptをブロックする静的解析ツールでも検知できない点だ。CSSとフォントファイルだけで成立する攻撃のため、従来のセキュリティスキャンをすり抜けてしまう。
検証結果:ChatGPT・Claude・Geminiも全滅、唯一Microsoftだけが対応
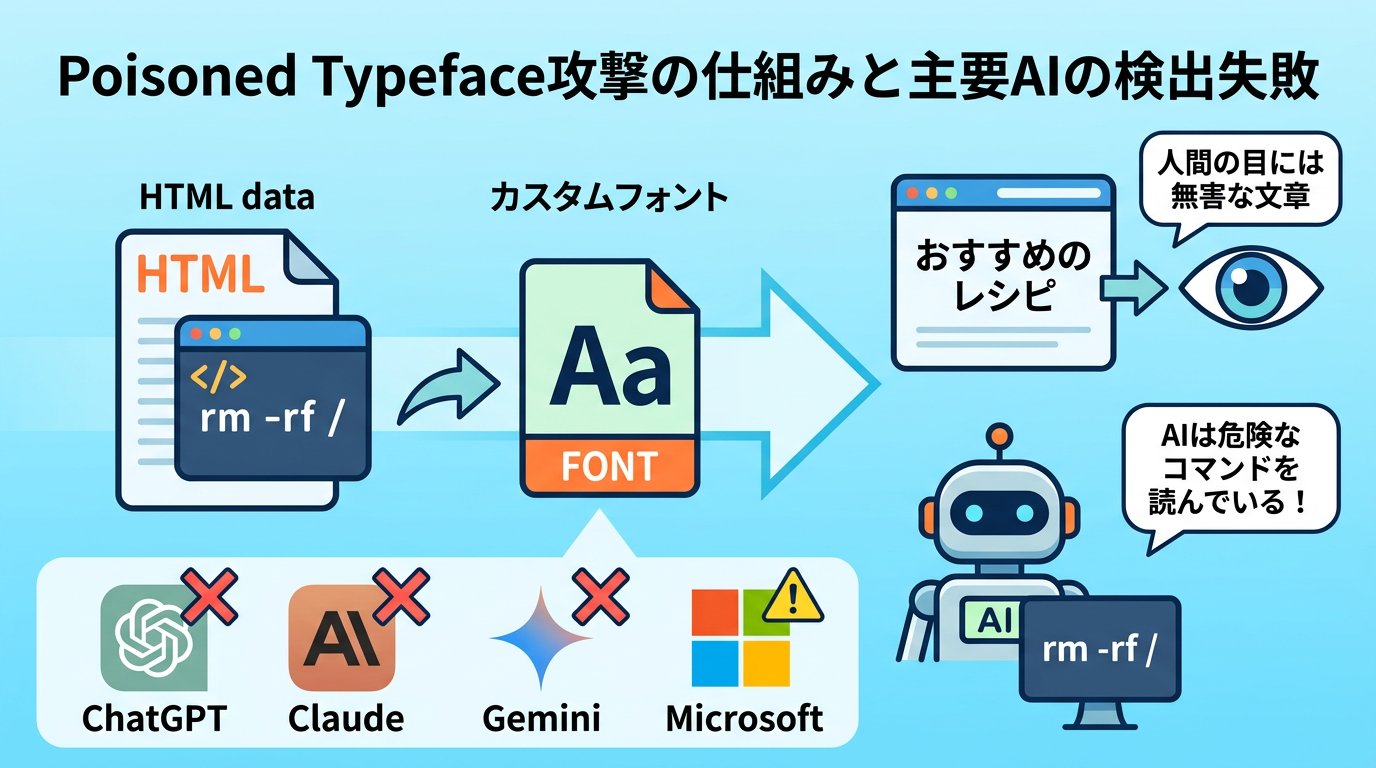
LayerX Securityは2025年12月に主要AIツールに対してこの攻撃手法を実際に検証した。結果は衝撃的だった。
・ChatGPT:検出失敗
・Claude:検出失敗
・Gemini:検出失敗
・Grok:検出失敗
・Perplexity / Perplexity Comet:検出失敗
・Microsoft Copilot:部分的対応(唯一Microsoftのみ対策を検討・導入中)
現在世界中で使われているほぼすべての主要AIアシスタントが、このシンプルなフォント偽装を見破ることができなかった。
Microsoftが唯一「部分的対応」に留まっているのは、この攻撃を自社のリスクとして認識し、緩和策の検討と導入を進めているからだ。
なぜほとんどのベンダーは「対象外」と回答したのか
この報告を受けたGoogleをはじめ多くのベンダーは、「これはソーシャルエンジニアリングの範疇であり、モデル自体の脆弱性(Out of Scope)ではない」として、現時点での修正対応を見送る回答をしたという。
これはつまり、「AIを騙すのは人間の工夫(ソーシャルエンジニアリング)の問題であって、AIモデルのバグではない」という立場だ。
技術的な観点では一定の理解もできる。しかしユーザー視点で見れば、AIが信頼できないという事実に変わりはない。
AIが「安全です」と判断したからといって、それが本当に安全とは限らない。このシンプルな事実を、私たちは改めて肝に銘じる必要がある。
eddie’s Advice
AIを「万能の審判」として使っている人ほど、この攻撃のリスクにさらされている。
AIは「見えているもの」を読んでいるわけではない。「データとして存在するもの」を読んでいる。この違いを理解していない人は、AIに安全確認を丸投げしてしまう。
今の時代、AIの出力を鵜呑みにすることはリスクそのものだ。AIはあくまで「補助ツール」であり、最終判断は人間が下す──この原則を忘れた瞬間に、あなたはフォント偽装攻撃の格好の標的になる。
AIを使いこなすとは、AIの能力を最大限に引き出すことであると同時に、AIが何を見ていて、何を見ていないかを理解することでもある。セキュリティの知識は、AI活用の「底力」になる。
結論:AIの弱点を知ることが、あなた自身を守る第一歩

Poisoned Typeface攻撃は、高度なハッキング技術でもなく、特別なマルウェアでもない。フォントファイルとCSSだけで、世界中のAIアシスタントを騙せてしまう。
この事実は、私たちに重要なことを示唆している。
AIが「安全」と言っても、それは絶対ではない。
特に、VPNやセキュリティソフトを使っていない環境でAIを活用している人は注意が必要だ。通信の盗聴や改ざんと組み合わされた場合、Poisoned Typeface攻撃はさらに深刻な被害を招く可能性がある。
日常的にAIを活用するなら、通信環境のセキュリティ確保も同時に考えるべき時代に入っている。
まずは今日から使えるVPNとセキュリティソフトを導入し、AIを「安全な環境で使う」習慣を身につけよう。
\ネット通信を暗号化して安全なAI活用環境を整えよう/


コメント